By @dnl0x00
In this post we will see how the average digit of the MNIST database of handwritten digits looks like.
The MNIST database of handwritten digits (see here) is a very popular dataset used by the machine learning research community for testing the performance of learning algorithms for the task of recognizing handwritten digits.
We will use the dataset that has been created in this post. The dataset can be also downloaded from here.
The following image is an example of the first 30 digits in the training set.
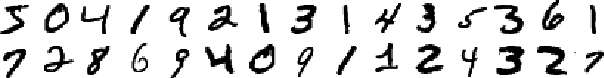
It has been created with the script shown at the bottom of this post. The distribution of the digits in the training set is as follows:
0: 5923 1: 6742 2: 5958 3: 6131 4: 5842 5: 5421 6: 5918 7: 6265 8: 5851 9: 5949
load('mnist.txt.gz'); % load the dataset
X = 255 - trainX; % invert the pixels
r = [];
for i = 0:9
rows = (trainY == i);
n = sum(rows);
d = reshape(sum(X(rows, :)) / n, 28, 28)';
r = [r, d];
end
imshow(r, [0, 255]);
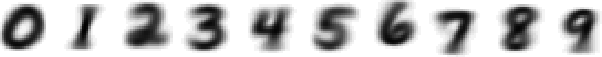
Source
1;
more off;
% load the dataset if it has not been loaded yet
if exist("trainX") == 0
load("mnist.txt.gz");
end
X = 255 - trainX; % invert the pixels
% show some examples
n = 15;
m = [];
for i = 0:n - 1
d1 = reshape(X(i + 1, :), 28, 28)';
d2 = reshape(X(i + 1 + n, :), 28, 28)';
m = [m, [d1; d2]];
end
imshow(m, [0, 255]);
% statistics about the distribution of the digits in the training set, i.e.
% count the number of occurrences of each digit
for i = 0:9
printf('%d: %d\n', i, sum(trainY == i));
end
display('press enter to see the averages ...');
pause;
% average the digits
r = [];
for i = 0:9
rows = (trainY == i);
n = sum(rows);
d = reshape(sum(X(rows, :)) / n, 28, 28)';
r = [r, d];
end
imshow(r, [0, 255]);